
Program Overview
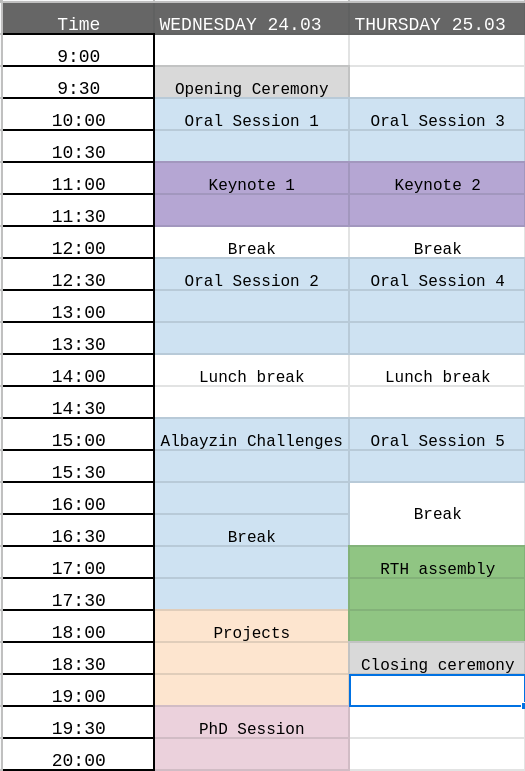
Technical Program
Wednesday, March 24 |
|
| Oral 1: Applications of Speech Technologies for Learning and Education Wednesday, 24 March 2021 Chair: Mireia Farrús |
|
| O1.1 10:00 – 10:10 |
Prosodic feature selection for automatic quality assessment of oral productions in people with Down syndrome (abs) (pdf) |
| David Escudero, Valentín Cardeñoso-Payo, Mario Corrales Astorgano and César González-Ferreras | |
| O1.2 10:10 – 10:20 |
Performance Comparison of Specific and General-Purpose ASR Systems for Pronunciation Assessment of Japanese Learners of Spanish (abs) (pdf) |
| Cristian Tejedor-García, Valentín Cardeñoso-Payo and David Escudero-Mancebo | |
| O1.3 10:20 – 10:30 |
An ASR-based Reading Tutor for Practicing Reading Skills in the First Grade: Improving Performance through Threshold Adjustment (abs) (pdf) |
| Yu Bai, Ferdy Hubers, Catia Cucchiarini and Helmer Strik | |
| O1.4 10:30 – 10:40 |
Impact of vowel reduction in L2 Chinese learners of Portuguese within and across word boundaries (abs) (pdf) |
| Catarina Realinho, Rita Gonçalves, Helena Moniz and Isabel Trancoso | |
| O1.5 10:40 – 10:50 |
Nativeness Assessment for Crowdsourced Speech Collections (abs) (pdf) |
| Diogo Botelheiro, Alberto Abad, João Freitas and Rui Correia | |
| Keynote 1 Wednesday, 24 March 2021 | |
| KN1 11:00 – 12:00 |
Characterizing and Assessing the Oral Reading Fluency of Young Readers (abs) |
| Gérard Bailly and Erika Godde | |
| Oral 2: Speech Processing and Acoustic Event Detection Wednesday, 24 March 2021 Chair: Luis Javier Rodríguez Fuentes |
|
| O2.1 12:30 – 12:40 |
Convolutional Recurrent Neural Networks for Speech Activity Detection in Naturalistic Audio from Apollo Missions (abs) (pdf) |
| Pablo Gimeno, Dayana Ribas, Alfonso Ortega, Antonio Miguel and Eduardo Lleida | |
| O2.2 12:40 – 12:50 |
Dual-channel eKF-RTF framework for speech enhancement with DNN-based speech presence estimation (abs) (pdf) |
| Juan Manuel Martín-Doñas, Antonio M. Peinado, Iván López-Espejo and Angel Gomez | |
| O2.3 12:50 – 13:00 |
An analysis of Sound Event Detection under acoustic degradation using multi-resolution systems (abs) (pdf) |
| Diego de Benito-Gorrón, Daniel Ramos and Doroteo T. Toledano | |
| O2.4 13:00 – 13:10 |
Speech Enhancement for Wake-Up-Word detection in Voice Assistants (abs) (pdf) |
| David Bonet, Guillermo Cámbara, Fernando López, Pablo Gómez, Carlos Segura, Jordi Luque and Mireia Farrús | |
| O2.5 13:10 – 13:20 |
An approach to intent detection and classification based on attentive recurrent neural networks (abs) (pdf) |
| Fernando Fernández-Martínez, David Griol, Zoraida Callejas and Cristina Luna-Jiménez | |
| O2.6 13:20 – 13:30 |
Contrasting the Emotions identified in Spanish TV debates and in Human-Machine Interactions (abs) (pdf) |
| Mikel de Velasco, Raquel Justo, Leila Ben Letaifa and M. Inés Torres | |
| O2.7 13:30 – 13:40 |
A proposal for emotion recognition using speech features, transfer learning and convolutional neural networks (abs) (pdf) |
| Roberto Móstoles, David Griol, Zoraida Callejas and Fernando Fernández-Martínez | |
| O2.8 13:40 – 13:50 |
Using Audio Events to Extend a Multi-modal Public Speaking Database with Reinterpreted Emotional Annotations (abs) (pdf) |
| Esther Rituerto-González, Clara Luis-Mingueza and Carmen Pelález-Moreno | |
| Albayzín Evaluation Challenges Wednesday, 24 March 2021 Chair: Eduardo Lleida and Alfonso Ortega |
|
| Ch.0 15:00 – 15:20 |
Presentation of the Albayzín Evaluation Challenges |
| Eduardo Lleida, Alfonso Ortega and Javier Tejedor | |
| Ch.1 15:20 – 15:30 |
Cenatav Voice Group System for Albayzin 2020 Search on Speech Evaluation |
| Jose M. Ramirez , Ana R. Montalvo and Jose R. Calvo | |
| Ch.2 15:30 – 15:40 |
Query-by-Example Spoken Term Detection using Attentive Pooling Networks at ALBAYZIN 2020 Evaluation: The AUDIAS-UAM System (abs) (pdf) |
| Juan Ignacio Álvarez-Trejos and Doroteo T. Toledano | |
| Ch.3 15:40 – 15:50 |
GTH-UPM System for Albayzin Multimodal Diarization Challenge 2020 (abs) (pdf) |
| Cristina Luna-Jiménez, Ricardo Kleinlein, Fernando Fernández-Martínez, José Manuel Pardo-Muñoz and José Manuel Moya-Fernández | |
| Ch.4 15:50 – 16:00 |
ViVoLAB Multimodal Diarization System for RTVE 2020 Challenge (abs) (pdf) |
| Victoria Mingote, Ignacio Viñals, Pablo Gimeno, Antonio Miguel, Alfonso Ortega and Eduardo Lleida | |
| Ch.5 16:00 – 16:10 |
The GTM-UVIGO System for Audiovisual Diarization 2020 (abs) (pdf) |
| Manuel Porta-Lorenzo, José Luis Alba-Castro and Laura Docío-Fernández | |
| Ch.6 16:10 – 16:20 |
The Biometric Vox System for the Albayzin-RTVE 2020 Speaker Diarization and Identity Assignment Challenge (abs) (pdf) |
| Roberto Font and Teresa Grau | |
| Ch.7 16:20 – 16:30 |
The CLIR-CLSP System for the IberSPEECH-RTVE 2020 Speaker Diarization and Identity Assignment Challenge (abs) (pdf) |
| Carlos Rodrigo Castillo-Sanchez and Leibny Paola Garcia-Perera | |
| Ch.8 16:30 – 16:40 |
Diarization and Identity Attribution Compatibility in the Albayzin 2020 Challenge (abs) (pdf) |
| Ignacio Viñals, Pablo Gimeno, Alfonso Ortega, Antonio Miguel and Eduardo Lleida | |
| 16:40 – 17:00 | Break |
| Ch.9 17:00 – 17:10 |
The Biometric Vox System for the Albayzin-RTVE 2020 Speech-to-Text Challenge (abs) (pdf) |
| Roberto Font and Teresa Grau | |
| Ch.10 17:10 – 17:20 |
The Vicomtech Speech Transcription Systems for the Albayzín-RTVE 2020 Speech to Text Transcription Challenge (abs) (pdf) |
| Aitor Álvarez, Haritz Arzelus, Iván G. Torre and Ander González-Docasal | |
| Ch.11 17:20 – 17:30 |
End to End AUDIAS-UAM system for Albayzin 2020 Speech to Text Challenge |
| Beltrán Labrador, Diego de Benito-Gorrón and Doroteo T. Toledano | |
| Ch.12 17:30 – 17:40 |
Sigma-UPM ASR Systems for the IberSpeech-RTVE 2020 Speech-to-Text Transcription Challenge (abs) (pdf) |
| Juan M. Perero-Codosero, Fernando M. Espinoza-Cuadros and Luis A. Hernández-Gómez | |
| Ch.13 17:40 – 17:50 |
BCN2BRNO: ASR System Fusion for Albayzin 2020 Speech to Text Challenge (abs) (pdf) |
| Martin Kocour, Guillermo Cámbara, Jordi Luque, David Bonet, Mireia Farrús, Martin Karafiát, Karel Veselý and Jan Černocký | |
| Ch.14 17:50 – 18:00 |
MLLP-VRAIN Spanish ASR Systems for the Albayzin-RTVE 2020 Speech-To-Text Challenge (abs) (pdf) |
| Javier Jorge, Adrià Giménez, Pau Baquero-Arnal, Javier Iranzo-Sánchez, Alejandro Pérez, Gonçal V. Garcés Díaz-Munío, Joan Albert Silvestre-Cerdà, Jorge Civera, Albert Sanchis and Alfons Juan | |
| Research and Development Projects Wednesday, 24 March 2021 Chair: Francesc Alías |
|
| Pr.1 18:00 – 18:10 |
Incorporation of an automatic module for the prediction of the quality of oral communication of people with Down syndrome in an educational video game (abs) (pdf) |
| David Escudero, Valentín Cardeñoso-Payo, Mario Corrales Astorgano, César González-Ferreras, Valle Flores Lucas, Lourdes Aguilar, Yolanda Martín-de-San-Pablo and Alfonso Rodríguez-de-Rojas | |
| Pr.2 18:10 – 18:20 |
CIRUSS Platform: Surgery Patient Empowerment by Stress and Anxiety Monitoring (abs) (pdf) |
| Sergio Figueras, Alejandro García-Caballero, Carmen Garcia Mateo, Laura Docio-Fernandez, Edward L. Campbell, Baltasar G. Perez-Schofield, Leandro Rodríguez-Liñares and Arturo J. Méndez | |
| Pr.3 18:20 – 18:30 |
Voice Restoration with Silent Speech Interfaces (ReSSInt) (abs) (pdf) |
| Inma Hernaez, Jose Andrés González-López, Eva Navas, Jose Luis Pérez Córdoba, Ibon Saratxaga, Gonzalo Olivares, Jon Sánchez de la Fuente, Alberto Galdón, Víctor García Romillo, Míriam González-Atienza, Tanja Schultz, Phil Green, Michael Wand, Ricard Marxer and Lorenz Diener | |
| Pr.4 18:30 – 18:40 |
The Vox Senes project: a study of segmental changes and rhythm variations on European Portuguese aging voice (abs) (pdf) |
| Catarina Oliveira, Ana Rita Valente, Luciana Albuquerque, Fábio Barros, Paula Martins, Samuel Silva and António Teixeira | |
| Pr.5 18:40 – 18:50 |
Hispabot-Covid19: the official Spanish conversational system about Covid-19 (abs) (pdf) |
| David Griol, David Pérez Fernández and Zoraida Callejas | |
| Pr.6 18:50 – 19:00 |
Project MEMNON: Extending Speech Production Studies to Silent Speech, Dynamic Sounds and Audiovisual Speech Synthesis (abs) (pdf) |
| Samuel Silva, António Teixeira, Nuno Almeida, Diogo Silva, David Ferreira and Conceição Cunha | |
| Pr.7 19:00 – 19:10 |
Towards conversational technology to promote, monitor and protect mental health (abs) (pdf) |
| Zoraida Callejas, David Griol, Kawtar Benghazi, Manuel Noguera, María Inés Torres, Raquel Justo, Anna Esposito, Gennaro Cordasco, Raymond Bond, Maurice Mulvenna, Edel Ennis, Siobhan O’Neill, Huiru Zheng, Matthias Kraus, Nicolas Wagner, Wolfgang Minker, Gavin McConvey, Matthias Hemmje, Michael Fuchs, Neil Glackin and Gérard Chollet | |
| Pr.8 19:10 – 19:20 |
GENIOVOX Project: Computational generation of expressive voice (abs) (pdf) |
| Oriol Guasch, Francesc Alías, Marc Arnela, Joan Claudi Socoró, Marc Freixes and Arnau Pont | |
| Ph.D. Thesis Wednesday, 24 March 2021 Chair: Carlos D. Martínez Hinarejos |
|
| PhD.1 19:30 – 19:40 |
Adverse Drug Reaction extraction on Electronic Health Records written in Spanish: A PhD Thesis overview (abs) (pdf) |
| Sara Santiso | |
| PhD.2 19:40 – 19:50 |
Design and Evaluation of Mobile Computer-Assisted Pronunciation Training Tools for Second Language Learning: a Ph.D. Thesis Overview (abs) (pdf) |
| Cristian Tejedor-García, Valentín Cardeñoso-Payo and David Escudero-Mancebo | |
| PhD.3 19:50 – 20:00 |
New tools for the differential evaluation of Parkinson’s disease using voice and speech processing (abs) (pdf) |
| Laureano Moro-Velazquez, Jorge Gomez-Garcia, Najim Dehak and Juan Ignacio Godino-Llorente | |
| PhD.4 20:00 – 20:10 |
Prosody training of people with Down syndrome using an educational video game (abs) (pdf) |
| Mario Corrales-Astorgano | |
| PhD.5 20:10 – 20:20 |
Self-supervised Deep Learning Approaches to Speaker Recognition: A Ph.D. Thesis Overview (abs) (pdf) |
| Umair Khan and Javier Hernando | |
Thursday, March 25 |
|
| Oral 3: ASR and NLP Techniques Thursday, 25 March 2021 Chair: David Griol |
|
| O3.1 10:00 – 10:10 |
A study of data augmentation for increased ASR robustness against packet losses (abs) (pdf) |
| María Pilar Fernández-Gallego and Doroteo T. Toledano | |
| O3.2 10:10 – 10:20 |
TRIBUS: An end-to-end automatic speech recognition system for European Portuguese (abs) (pdf) |
| Carlos Carvalho and Alberto Abad | |
| O3.3 10:20 – 10:30 |
mintzai-ST: Corpus and Baselines for Basque-Spanish Speech Translation (abs) (pdf) |
| Thierry Etchegoyhen, Haritz Arzelus, Harritxu Gete Ugarte, Aitor Alvarez, Ander González-Docasal and Edson Benites Fernandez | |
| O3.4 10:30 – 10:40 |
Confidence Measures for Interactive Neural Machine Translation (abs) (pdf) |
| Angel Navarro and Francisco Casacuberta | |
| O3.5 10:40 – 10:50 |
Sentence Embeddings and Sentence Similarity for Portuguese FAQs (abs) (pdf) |
| Nuno Carriço and Paulo Quaresma | |
| O3.6 10:50 – 11:00 |
Domain Adaptation in Dialogue Systems using Transfer and Meta-Learning (abs) (pdf) |
| Rui Ribeiro, Alberto Abad and José Lopes | |
| Keynote 2 Thursday, 25 March 2021 | |
| KN2 11:00 – 12:00 |
Diverse Conversational Spoken Language Generation (abs) |
| Antonio Bonafonte | |
| Oral 4: Speech Synthesis and Multimodal Processing Thursday, 25 March 2021 Chair: Helena Moniz |
|
| O4.1 12:30 – 12:40 |
Automatic Speaker Adaptation Assessment Based on Objective Measures for Voice Banking Donors (abs) (pdf) |
| Agustin Alonso, Victor García, Inma Hernaez, Eva Navas and Jon Sanchez | |
| O4.2 12:40 – 12:50 |
Data-driven analysis of nasal vowels dynamics and coordination: Results for bilabial contexts (abs) (pdf) |
| Conceição Cunha, Nuno Almeida, Jens Frahm, Samuel Silva and António Teixeira | |
| O4.3 12:50 – 13:00 |
Analysis of Visual Features for Continuous Lipreading in Spanish (abs) (pdf) |
| David Gimeno-Gómez and Carlos-D. Martínez-Hinarejos | |
| O4.4 13:00 – 13:10 |
Implementation of neural network based synthesizers for Spanish and Basque (abs) (pdf) |
| Victor Garcia, Inma Hernaez and Eva Navas | |
| O4.5 13:10 – 13:20 |
Multi-view Temporal Alignment for Non-parallel Articulatory-to-Acoustic Speech Synthesis (abs) (pdf) |
| Jose Andres Gonzalez Lopez, Miriam González Atienza, Alejandro Gómez Alanis, José Luis Pérez Córdoba and Phil D. Green | |
| O4.6 13:20 – 13:30 |
Generation of Synthetic Sign Language Sentences (abs) (pdf) |
| Aitana Villaplana and Carlos David Martinez Hinarejos | |
| O4.7 13:30 – 13:40 |
Contribution of vocal tract and glottal source spectral cues in the generation of happy and aggressive [a] vowels (abs) (pdf) |
| Marc Freixes, Francesc Alías and Joan Claudi Socoró | |
| O4.8 13:40 – 13:50 |
The age effects on EP vowel production: an ultrasound pilot study (abs) (pdf) |
| Luciana Albuquerque, Ana Rita Valente, Fábio Barros, António Teixeira, Samuel Silva, Paula Martins and Catarina Oliveira | |
| Oral 5: Speaker Characterization and Diarization Thursday, 25 March 2021 Chair: Alberto Abad |
|
| O5.1 15:00 – 15:10 |
Exploring Transformer-based Language Recognition using Phonotactic Information (abs) (pdf) |
| David Romero, Luis Fernando D’Haro and Christian Salamea | |
| O5.2 15:10 – 15:20 |
Adversarial Transformation of Spoofing Attacks for Voice Biometrics (abs) (pdf) |
| Alejandro Gomez-Alanis, Jose A. Gonzalez and Antonio M. Peinado | |
| O5.3 15:20 – 15:30 |
Active correction for speaker diarization with human in the loop (abs) (pdf) |
| Yevhenii Prokopalo, Meysam Shamsi, Loic Barrault, Sylvain Meignier and Anthony Larcher | |
| O5.4 15:30 – 15:40 |
An Automatic System for Dementia Detection using Acoustic and Linguistic Features (abs) (pdf) |
| Miriam Gonzalez-Atienza, Antonio M. Peinado and Jose A. Gonzalez-Lopez | |
| O5.5 15:40 – 15:50 |
Alzheimer’s Dementia Detection from Audio and Language Modalities in Spontaneous Speech (abs) (pdf) |
| Edward L. Campbell, Laura Docio-Fernandez, Javier Jiménez-Raboso and Carmen Gacia-Mateo | |